
Leía en el blog de la Biblioteca del Congreso de EEUU (EN) un artículo sobre las dificultades que están encontrando sus funcionarios a la hora de asegurar la persistencia del contenido publicado en su página.
El tema no es para nada baladí, y un servidor ya ha hablado de todo esto por diferentes artículos en mi web personal.
El caso es que el contenido en Internet es efímero.
Hay tantas razones por las que, de pronto, un contenido puede dejar de estar accesible, que conforme más crece el conocimiento humano vertido en la Red, más dificultades encontramos para asegurar su acceso.
Entre las razones:
- Que el contenido se elimine.
- Que el contenido cambie de URL.
- Que el sistema de gestión de contenido falle.
- Que el dominio y/o el servidor cambien o dejen de funcionar.
- Que alguna de las tecnologías que permiten el visionado de dicha información acabe quedando obsoleta.
- Etc, etc, etc…
Un servidor tiene en su página personal más de 4.000 publicaciones. Y te puedo asegurar que prácticamente cada semana los sistemas de alerta que tengo definidos me avisan de que algún enlace, tanto interno como externo, ha dejado de estar accesible, lo que me obliga cada semana a entrar en dichos contenidos, ver si en efecto ya no son accesibles, y actualizarlos.
Un trabajo que me roba bastante tiempo.
Pues ahora imagínate hacer esto mismo pero con una página como la de la Biblioteca del Congreso de los EEUU, que fácilmente tendrá alrededor de 60.000 de URLs internas.
O imagínate algo como la Wikipedia, con millones de páginas…
Así pues, los administradores se preguntan qué sistemas automatizados podrían usar para realizar el scrapping, y lo cierto es que no hay una solución sencilla.
¿La obvia y que todos utilizamos? Aprovechar el valor devuelto por el protocolo HTTP que arroja cada web cuando entramos.
Por si no lo sabes, estos valores son un número de tres cifras, de forma que:
- Valores 200: significa que la URL devuelve información correctamente.
- Valores 300: Que hubo algún tipo de redirección.
- Valores 400 y 500: Que hubo algún tipo de error.
¿Cuál es el problema de este sistema?
Pues que cuando una web te devuelve un valor 200, lo único que te dice es que la URL funciona. Pero lo mismo el contenido que hay está obsoleto, o incluso vacío.
Y con los valores 400 y 500 (como el típico error 404 que habrás visto en muchas páginas), tampoco son del todo fiables. Puede ser que justo cuando la araña pasa por esa URL en particular el servidor no puede mostrarle el contenido, y quedará marcado como página con error aunque en efecto esté funcionando.
Algo que, para colmo, pasa muy habitualmente con este tipo de sistemas de scrapping automatizados. Puedo dar fe que de 10 potenciales URLs con error que me muestra la herramienta que uso, fácilmente 3 o 4 son falsos positivos, lo que te obliga, sí o sí, a revisarlos A MANO.
En fin, que ni siquiera ellos llegan a una conclusión buena para todos: Hay que hacer una segunda revisión a mano.
Tras meses de trabajo, han llegado al corolario de que de su web, el 52% del contenido sigue siendo accesible, el 7% sigue accesible pero ha cambiado de URL, el 21% se ha perdido, y el 20% sigue online pero inaccesible de alguna manera.
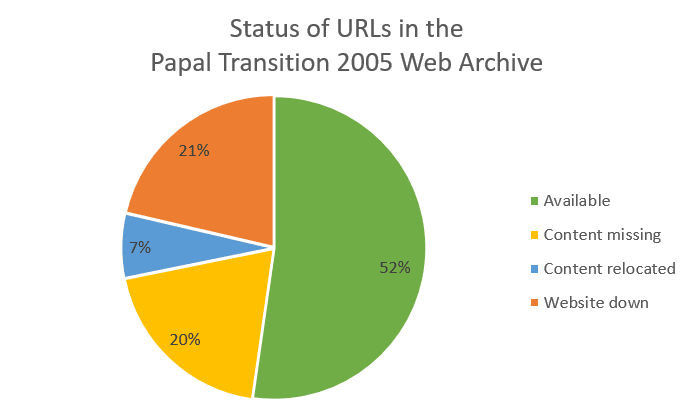
Hablamos de que prácticamente la mitad del contenido ya no es, de una u otra manera, accesible. El 41%, concretamente.
Es un problema base del sistema de distribución de contenido en Internet, y aunque en efecto haya proyectos como el de Archive.org que intentan guardar copias de las webs tal y como estaban en un momento dado, está claro que aún nos falta muchísimo para crear un ecosistema que sea lo suficientemente robusto y fiable por sí mismo.
En CyberBrainers hacemos informes, tutoriales y análisis de mercado en temas candentes para nuestros clientes, ya sean de negocio o puramente reputacionales. Si necesitas conocer cómo le va a la competencia, a tu propia empresa, o simplemente conocer qué opina la gente sobre algún tema en particular, escríbenos y ponemos nuestras máquinas y analistas a escuchar.
Pablo F. Iglesias es el fundador de CyberBrainers, consultora especializada en blindaje reputacional, construcción de autoridad digital y asesoramiento a víctimas de fraude online, de EliminamosContenido, el servicio de desindexación y eliminación de contenido dañino en Internet, y del sello editorial Ediciones PY.
Speaker internacional, Experto en ayudar a referentes digitales, influencers y marcas personales a diversificar su presencia y construir reputaciones inquebrantables. Especialista en transformar la presencia online de referentes a través de estrategias de diversificación digital, posicionamiento SEO, apariciones en medios y blindaje preventivo ante crisis reputacionales.
Reconocido divulgador en Seguridad TIC, ganador de varios premios ESET, Bitácoras y Red Seguridad a la divulgación en Ciberseguridad, colaborador habitual en varios programas de televisión, radio y periódicos, y representante del emprendimiento español en Silicon Valley.
Autor de seis libros y host del videopodcast enCLAVE DIGITAL.
Actualmente asesora a grandes patrimonios y a víctimas de fraudes online, demostrando con hechos su filosofía de diversificación y gestión de riesgo.





